Abstract
Reinforcement learning (RL) in low-data and risk-sensitive domains requires performant and flexible deployment policies that can readily incorporate constraints during deployment. One such class of policies are the semi-parametric H-step lookahead policies, which select actions using trajectory optimization over a dynamics model for a fixed horizon with a terminal value function. In this work, we investigate a novel instantiation of H-step lookahead with a learned model and a terminal value function learned by a model-free off-policy algorithm, named Learning Off-Policy with Online Planning (LOOP). We provide a theoretical analysis of this method, suggesting a tradeoff between model errors and value function errors and empirically demonstrate this tradeoff to be beneficial in deep reinforcement learning. Furthermore, we identify the "Actor Divergence" issue in this framework and propose Actor Regularized Control (ARC), a modified trajectory optimization procedure. We evaluate our method on a set of robotic tasks for Offline and Online RL and demonstrate improved performance. We also show the flexibility of LOOP to incorporate safety constraints during deployment with a set of navigation environments. We demonstrate that LOOP is a desirable framework for robotics applications based on its strong performance in various important RL settings.
H-step Lookahead with a Learned Model and Value Function
H-step lookahead, when using a learned model and a learned value function presents a tradeoff between the model-errors and value errors. Theorem 1 below shows the exact tradeoff. For more details and proof refer to the paper.

Method
Naively using H-step lookahead leads to computationally expensive value updates. We present a computationally efficient framework called LOOP which:
1. Uses the H-step lookahead as the deployment policy
2. Collects the environment interactions in the replay buffer
3. Learns the value function with the replay buffer using an off-policy algorithm. Update the dynamics function using supervised learning
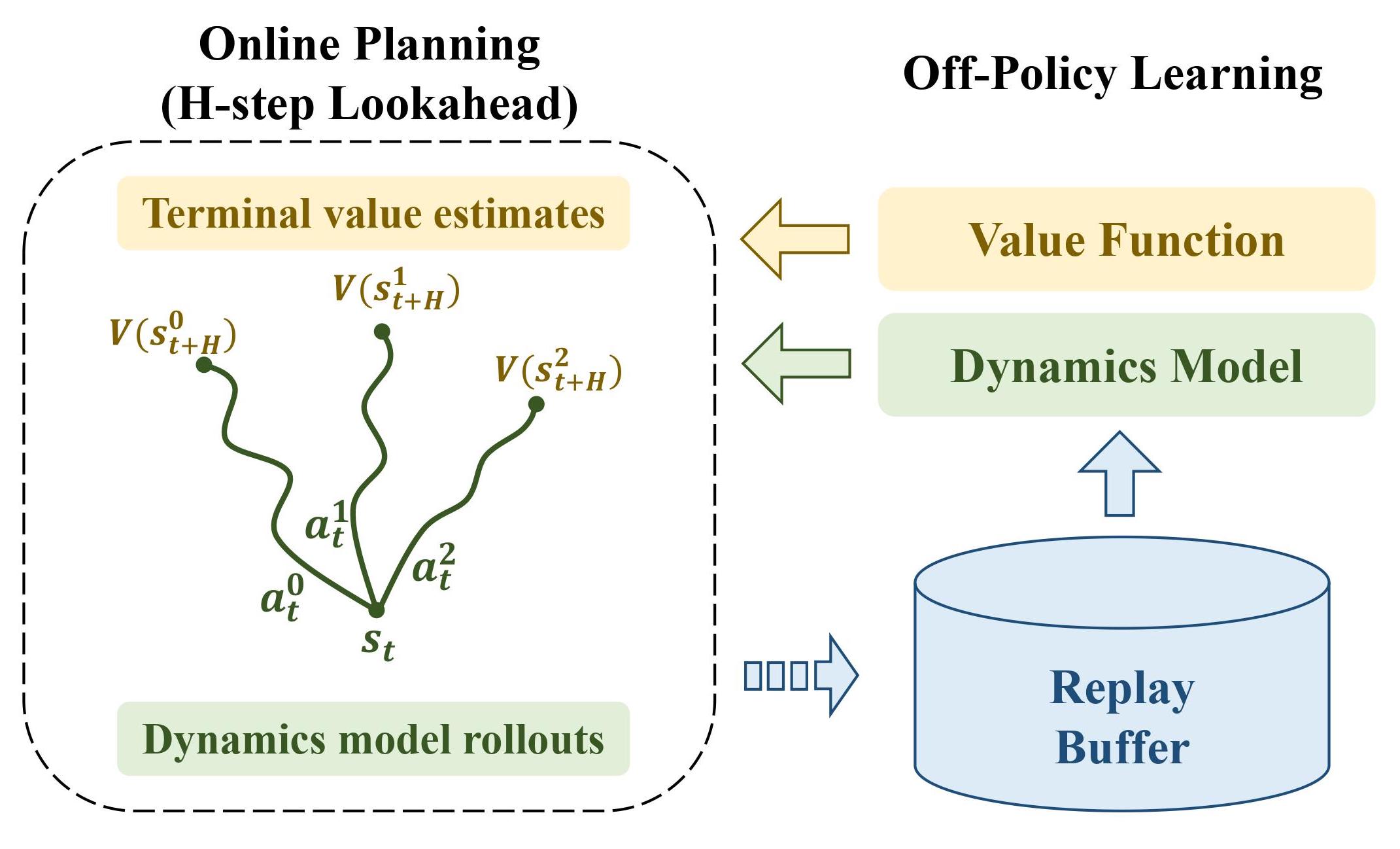
To account for the distribution shift in the H-step lookahead policy and the policy used to update the value function (we call this Actor Divergence), we propose Actor Regularized Control (ARC) which runs as a subroutine in LOOP. ARC frames the policy improvement with H-step lookahead as the following constrained optimization:
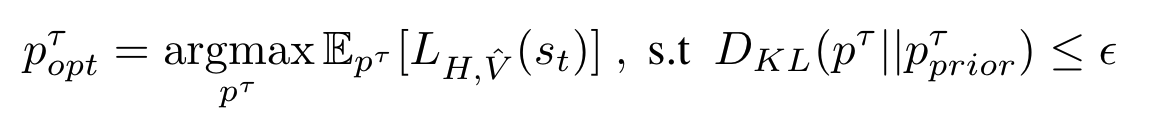
The prior is set to the parameterized policy of the off-policy algorithm. We use the closed-form solution to the optimization above and form an iterative importance sampling based update as follows:
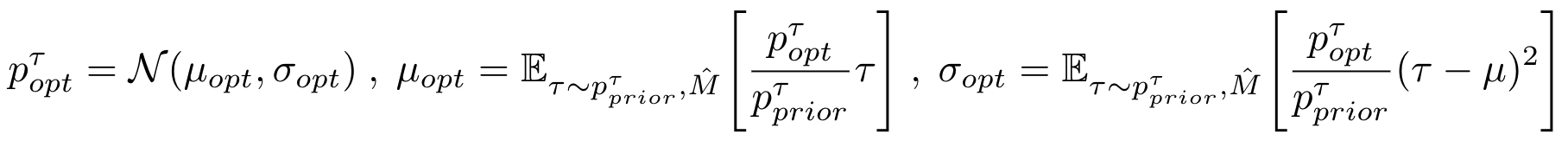
Results
Online Reinforcement Learning
LOOP-SAC outperforms baselines SAC, SAC-VE, PETS-restricted. It performs competitively to MBPO while outperforming it significantly in PenGoal-v1 and Claw-v1.
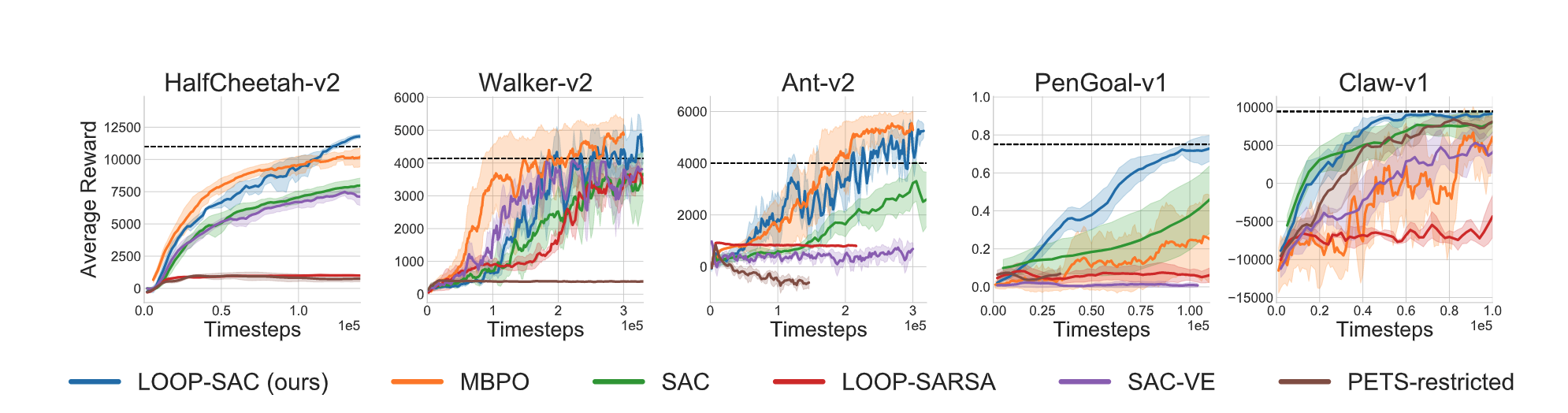
We find ARC to be crucial to the success of LOOP as it reduces the Actor Divergence. Figure below shows an ablation with ARC:
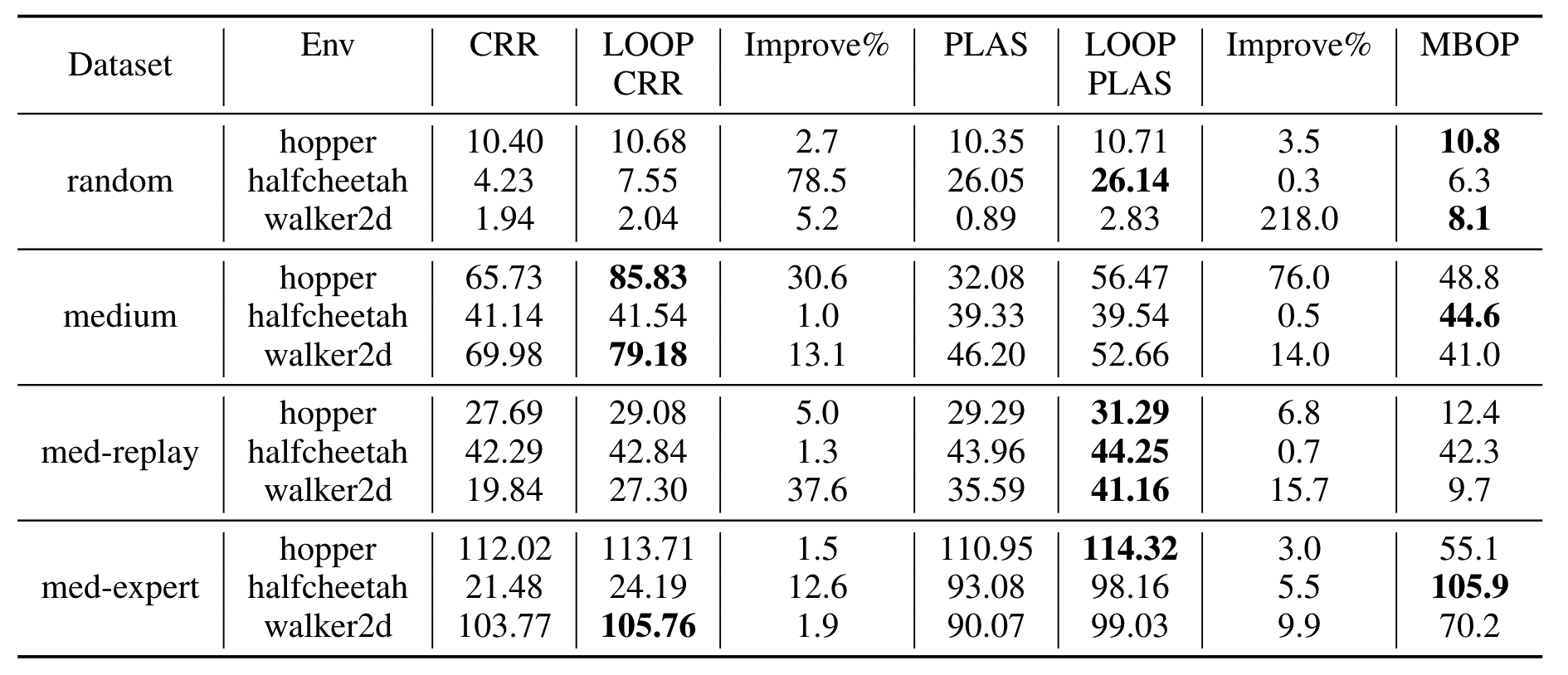
Offline Reinforcement Learning
LOOP offers an average improvement of 15.91% over CRR and 29.49% over PLAS on the complete D4RL MuJoCo Locomotion dataset.
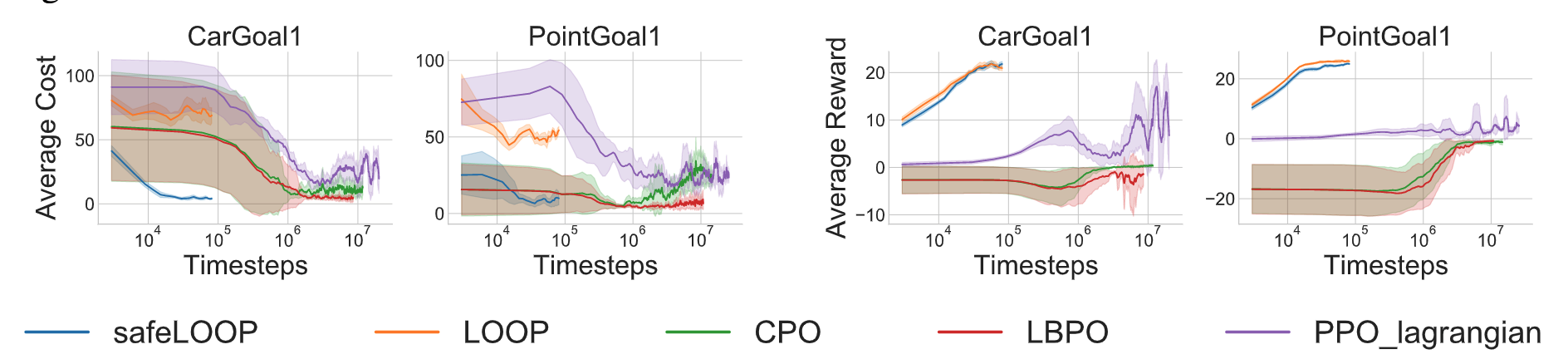
Safe Reinforcement Learning
SafeLOOP reaches a higher reward than CPO, LBPO and PPO-lagrangian, while being orders of magnitude faster. SafeLOOP also achieves a policy with a lower cost faster than the baselines.
Paper

Learning Off-Policy with Online Planning
Harshit Sikchi, Wenxuan Zhou, David Held
In Conference of Robot Learning (CoRL), 2021.
Acknowledgements
This material is based upon work supported by the United States Air Force and DARPA under Contract No. FA8750-18-C-0092, LG Electronics, and the National Science Foundation under Grant No. IIS-1849154.