ν Sony AI, φ Meta AI
* Equal Contribution, + Equal Advising

Note: The blogs serves to promote informal understanding of the ideas in our work. For a more formal read, check out our paper.
Talk and Overview
RLZero

Figure 1: Overview of the RLZero approach
Reinforcement Learning lacks an interpretable window to the agent. Specifying a task to the agent requires desiging a reward function, which experienced researchers struggle to do. We propose RLZero as a way to design a small language promptable generalist RL agent. RLZero provides two advances over prior methods:
a) Zero-shot: During text time, there is no further training or environment interactions required to generate a policy given a task description
b) Unsupervised: We do not use any task labels to map language to skills and our approach remains completely unsupervised.
How it works?
Step 1 : Imagine
Given a task description in natural language, RLZero uses a video model to generate imagination of the task.

Figure 2: Generated video clip for Walker environment using the prompt 'do lunges'
In this stage, the agent can be prompted with a real video (cross-embodiment) rather than one generated by a video model.

Figure 3: RLZero can use a video scraped from YouTube or AI generated at this stage.
Step 2: Project
The imagination might differ in the domain or the dynamics when compared to the agent. Each frame of the imagined video is projected with a real observation that the agent encountered in its past environmental interactions.

Figure 4: SigLIP is used to do image retrieval, finding the closest frame in the prior interaction dataset.
Step 3: Zero-shot Imitation with Behavior Foundation Models (BFM)
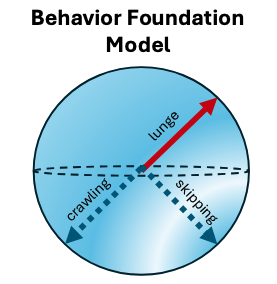
Figure 4: Skills learned as points on a hypersphere of a BFM
RLZero uses agent's past interaction data to learn a wealth of skills. This becomes possible now with advances in Zero-shot Reinforcement Learning [ 1, 2, 3 ]. This model is referred to as a Behavior Foundation Model (BFM). Using the real observations of the agent, we can compute the policy that solves the observation-only imitation problem in closed form using BFMs.